

Reducing database roundtrips for bulk actions using JSON
For health and other reasons, unfortunately it’s been a while since I published my last article. In the meantime, starting my blog at lowcoding.eu, a job change, several OutSystems certifications and preparing a speech for the ONE Conference 2025 in Lisbon have dominated my agenda. Although my presentation wasn’t selected for the ONE Conference 2025, I’m excited to share the content with you earlier than planned, right here on my blog.
What is it about?
In OutSystems, the challenge often arises of having to process multiple data records at once. In my previous articles you can find some examples of how to efficiently load lists from the database and display them on the screen (i.e. filtering, pagination, nested data structures). But what if you need to manipulate multiple data records?
If you have a look at the OutSystems documentation, you can find a very important recommendation regarding performance:
Avoid database operations within loops.
Obviously, every time an action flow in Outsystems accesses the database, a connection must be established via the network and the system has to wait for the response, a so-called database round trip. This takes time, and when repeated in a loop, the delays accumulate significantly.
The Simple but Limited Solution
As a solution, the OutSystems documentation recommends using an Advanced SQL with a bulk script. Examples mentioned there are:
Bulk Delete
If you want to delete all data records or only those to which a specific condition applies, you don’t have to be a great SQL expert to find the solution. For example, you can use the following statement to completely empty an entity:
DELETE FROM {Entity}Or use the following to delete all data records that were created before the specific date @DeleteDate:
DELETE FROM {Entity} WHERE {Entity}.[CreatedOn] < @DeleteDateThe task becomes more complex if you want to delete a list of data records based on their Ids. The first approach that comes to mind, which also can be found in some exercises, creates a round trip for each entry to be deleted and should therefore not be used:
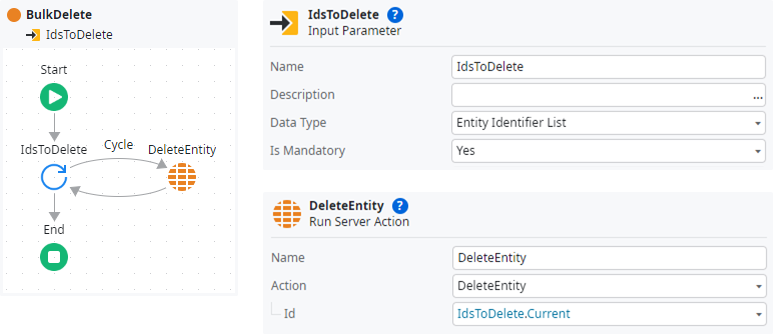
More elegant is to use the following Advanced SQL with an IN clause based on the parameter @IdLiterals with Expand Inline set to Yes:
DELETE FROM {Entity} WHERE {Entity}.[Id] IN (@IdLiterals)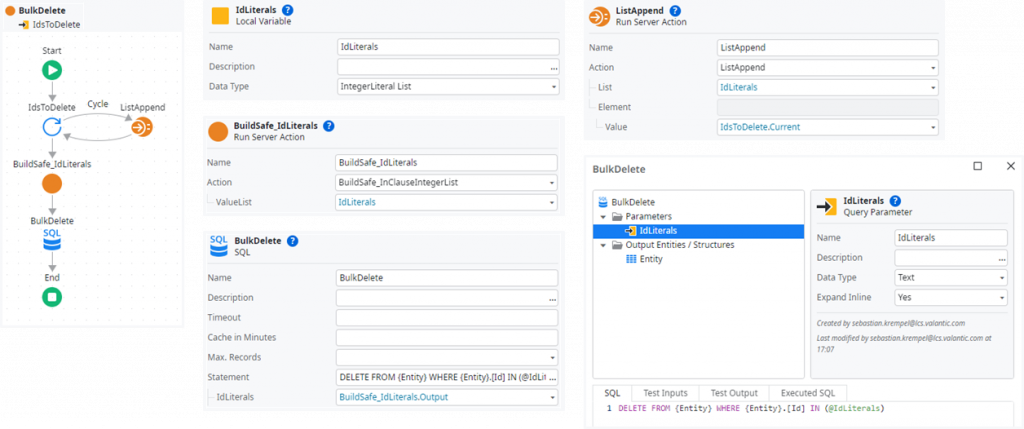
However, there is a restriction to consider that you may only come across during later tests or, even worse, during productive operation. The underlying DBMS has a specific limit for the IN clause (e.g. 1000 items in Oracle) or max. statement length, which can become a problem depending on the number or format of the Ids.
Of course you could still process the bulk deletion in batches to reduce the number of roundtrips, but what if your statement is to delete all records except the specified list (NOT IN(@IdLiterals))?
Bulk Update
Another example for a bulk action is updating records. The following statement, for instance, sets the IsArchive flag for all entries that were last changed before the specific date @ArchiveDate:
UPDATE {Entity} SET {Entity}.[IsArchive] = 1
WHERE {Entity}.[UpdatedOn] < @ArchiveDateYou could also set values dynamically based on a calculation or sub query, but what if you need to pass over individual values from your server action?
A Smarter Approach with JSON
To overcome the hurdles we’ve discovered so far, there is a very handy feature on the database side, which can be combined nicely with an integrated function in OutSystems. The magic word is JSON.
Both MS SQL and Oracle (used by O11) as well as Aurora PostgreSQL (used by ODC) support JSON functions. This allows us to serialize the list of Ids on the OutSystems application server into JSON and safely pass it over to the database as SQL parameter of type Text.
Bulk Delete
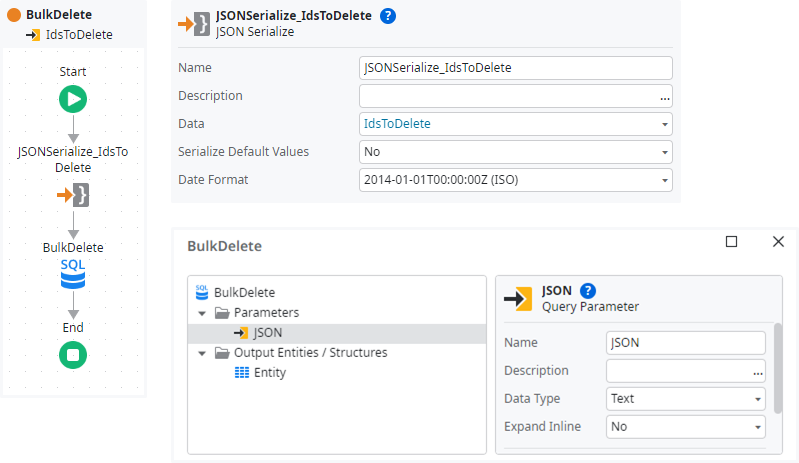
The SQL parameter @JSON contains a valid JSON string generated by the OutSystems platform, Expand Inline is not necessary so we do not need to sanitize with BuildSafe_InClause….
[1,2,3]Unfortunately, all three DBMS use different syntax to parse the JSON, so we need to implement depending on the environment. We also should strongly type the parsed JSON values, which especially is important for SQL Server that has a known limitation to bind the dynamic rowset metadata properly at execution time. Please find the corresponding Database Data Types in the OutSystems documentation.
-- O11 with SQL Server
DELETE FROM {Entity} WHERE {Entity}.[Id] IN (
SELECT CAST([value] AS BIGINT)
FROM OPENJSON(@JSON)
)
-- O11 with Oracle
DELETE FROM {Entity} WHERE {Entity}.[Id] IN (
SELECT value
FROM JSON_TABLE(@JSON, '$[*]' COLUMNS(value NUMBER(20) PATH '$'))
)
-- ODC with PostgreSQL
DELETE FROM {Entity} WHERE {Entity}.[Id] IN (
SELECT CAST(value AS BIGINT)
FROM jsonb_array_elements_text(@JSON::jsonb) AS t(value)
)Bulk Insert/Update
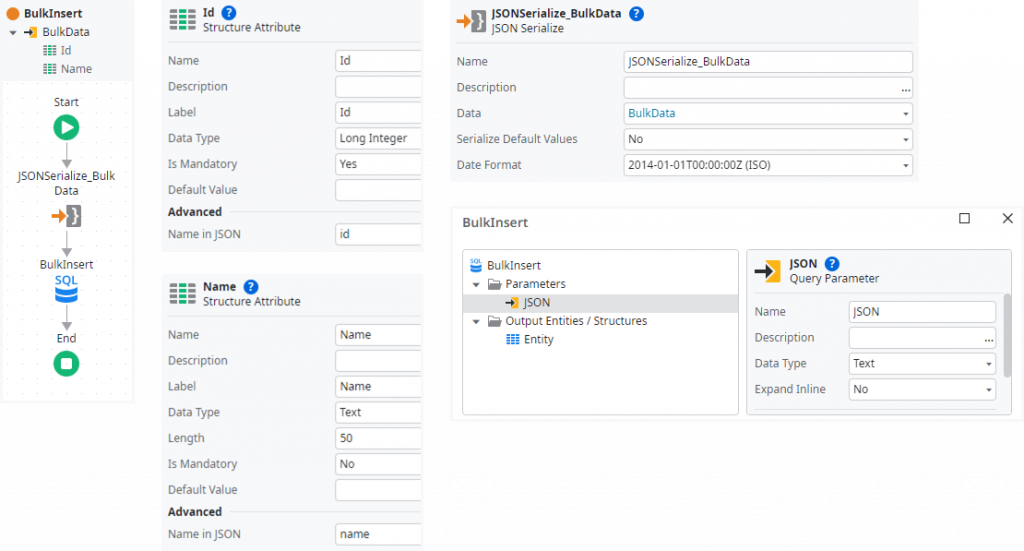
You probably already guessed it, these JSON functions are not limited to parsing a flat array of Ids, but can also parse structured data objects with multiple attributes, even nested objects. This allows us to transfer several data records in a single database roundtrip and use them for a bulk insert or update.
First, we create a structure in OutSystems that defines the format of the data to be transferred. Even if it is possible to only refer certain attributes or sub-objects in SQL, for performance reasons it is advisable to optimize the structure to a minimal number of attributes. In this way, not only the network traffic to the database can be reduced, but also the size of the database transaction log. As these identifiers must be hard-coded in the SQL statement, I also recommend explicitly setting the “Name in JSON” property to avoid errors when structure attributes are renamed at a later date.
[
{ "id": 1, "name": "A" },
{ "id": 2, "name": "B" },
{ "id": 3, "name": "C" }
]
-- O11 with SQL Server
INSERT INTO {Entity} (Id, Name)
SELECT * FROM OPENJSON(@JSON) WITH (
Id BIGINT '$.id',
Name NVARCHAR(50) '$.name'
)
-- O11 with Oracle
INSERT INTO {Entity} (Id, Name)
SELECT * FROM JSON_TABLE(@JSON, '$[*]' COLUMNS (
Id NUMBER(20) PATH '$.id',
Name VARCHAR2(50) PATH '$.name'
))
-- ODC with PostgreSQL
INSERT INTO {Entity} (Id, Name)
SELECT
CAST(elem->>'id' AS BIGINT),
elem->>'name'
FROM jsonb_array_elements(@JSON::jsonb) AS elemAnd of course, bulk updates can be implemented in the similar way:
-- O11 with SQL Server
UPDATE {Entity} SET
{Entity}.[Name] = J.Name
FROM {Entity} JOIN OPENJSON(@JSON) WITH (
Id BIGINT '$.id',
Name NVARCHAR(50) '$.name'
) AS J ON {Entity}.[Id] = J.Id
-- ODC with PostgreSQL
UPDATE {Entity} E SET
Name = J.Name
FROM (
SELECT
CAST(elem->>'id' AS BIGINT) AS Id,
elem->>'name' AS Name
FROM jsonb_array_elements(@JSON::jsonb) AS elem
) AS J WHERE E.Id = J.IdOracle does not support UPDATE … FROM … statements. Here you need to implement sub queries per attribute you want to set. As this quickly becomes a little cluttered, especially if there are several attributes to be set, I do not want to give an example here. In such cases, I recommend using the solution described in the following.
The Ultimate Bulk Handling Strategy
Everything described so far sounds nice, but what do you need it for in real life? Bulk deletes are suitable for data purging, bulk inserts can be used for classic data imports, bulk updates might be helpful when updating master-detail data (e.g. items of an order or invoice). But for me, the method shown above will really pay off when synchronizing data. An example of this scenario is integration services that cache data from external sources in an own entity. Wouldn’t it be nice if we could even let the database decide whether a record is to be added or updated?
Merge
Let me introduce the SQL MERGE statement, which allows to compare two tables based on a match condition and execute different data manipulations based on whether there is a match or a record is only found on one side of the comparison.
MERGE [Target] USING [Source] ON [MatchCondition]
WHEN MATCHED THEN ...
WHEN NOT MATCHED BY Target THEN ...
WHEN NOT MATCHED BY Source THEN ...;Please notice the semicolon at the end, which is mandatory to close the MERGE statement. If necessary, you can include additional execution conditions: WHEN MATCHED AND … THEN. However, these should not be confused with the match condition:
- The match condition defines how records are to be considered a match in the comparison.
- The execution conditions define whether the corresponding data manipulation should actually be executed in the event of a (non-)match.
So how to adopt this to our small sample? Here we go:
-- O11 with SQL Server
MERGE {Entity} AS Target USING (
SELECT * FROM OPENJSON(@JSON) WITH (
Id INT '$.id',
Name NVARCHAR(50) '$.name'
)
) AS Source ON Source.Id = Target.Id
WHEN MATCHED THEN
UPDATE SET Target.Name = Source.Name
WHEN NOT MATCHED BY Target THEN
INSERT (Id, Name) VALUES (Source.Id, Source.Name)
WHEN NOT MATCHED BY Source THEN
DELETE;Looks cool, doesn’t it? But what’s about O11 with Oracle and ODC with PostgreSQL? Oracle cannot distinguish whether it’s NOT MATCHED BY target or by source in the MERGE statement. So it can only handle inserts and updates:
-- O11 with Oracle
MERGE INTO {Entity} Target
USING (
SELECT * FROM JSON_TABLE(@JSON, '$[*]' COLUMNS (
Id NUMBER(20) PATH '$.id',
Name VARCHAR2(50) PATH '$.name'
))
) Source ON (Target.Id = Source.Id)
WHEN MATCHED THEN
UPDATE SET Target.Name = Source.Name
WHEN NOT MATCHED THEN
INSERT (Id, Name) VALUES (Source.Id, Source.Name)Please notice, that there is no tailing semicolon, as this is handled by OutSystems automatically for Oracle. For the deletes we need to implement a second statement. Unfortunately, the Advanced SQL node for Oracle does not allow separating several statements by a semicolon. Thus we are forced to do the deletion in a separate SQL node and end up with two database roundtrips:
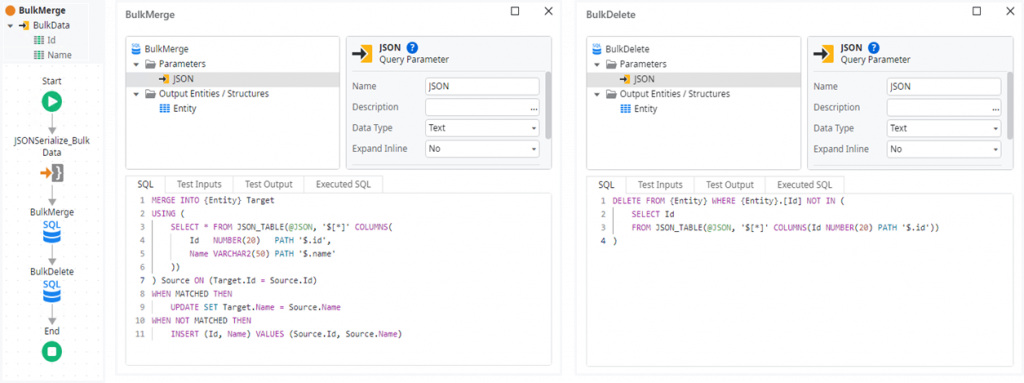
DELETE FROM {Entity} WHERE {Entity}.[Id] NOT IN (
SELECT Id
FROM JSON_TABLE(@JSON, '$[*]' COLUMNS (Id NUMBER(20) PATH '$.id'))
)PostgreSQL only supports the MERGE statement starting with version 15, but ODC uses an earlier version. The workaround at hand is using a combined INSERT/UPDATE with a DELETE following in the same Advanced SQL – so it is still just one roundtrip:
-- ODC with PostgreSQL
INSERT INTO {Entity} (id, name)
SELECT
CAST(elem->>'id' AS BIGINT),
elem->>'name'
FROM jsonb_array_elements(@JSON::jsonb) AS elem
ON CONFLICT (id) DO UPDATE
SET name = EXCLUDED.name;
DELETE FROM {Entity}
WHERE id NOT IN (
SELECT CAST(elem->>'id' AS BIGINT)
FROM jsonb_array_elements(@JSON::jsonb) AS elem
);By leveraging JSON and MERGE statements in Advanced SQL, you can reduce database roundtrips to a single call, significantly boosting performance and scalability for bulk data operations in OutSystems.
I hope this article was to your liking and will be of practical help for your future OutSystems projects. I would be pleased if you follow me on my social media accounts and leave some claps on medium. In case you have any questions left open or have tips for me to improve, please contact me via LinkedIn, medium or my OutSystems profile.